1.1 데이터과학이란?
1946년 미국 펜실베니아대학의 존 에커트와 존 모클리에 의해 처음 개발되었던 현대 디지털 컴퓨터는 1960년대 이후 현실에 응용되기 시작하여 지난 반세기 동안 엄청난 발전을 이룩하고 우리 사회의 많은 변화를 가져왔다. 특히 1980년대 이후 컴퓨터와 컴퓨터의 연결이 시작되고, 개인용 컴퓨터가 활성화되고, 유무선 정보통신 기술이 발전되면서 최근에는 전 세계의 거의 모든 컴퓨터가 유무선 인터넷을 통하여 연결되어 있다. 2000년대 이후에는 성능이 우수한 컴퓨터가 소형화 되면서 전화기와 연결한 스마트폰이 탄생되어 우리 사회에 많은 변화를 가져왔다.
이와 같은 컴퓨터와 정보통신 기술의 발전은 최근에 더욱 심화되어 알파고와 같은 인간의 지능을 능가하는 인공지능(artificial intelligence; AI)을 만들어내고 있다. 또한 모든 전자기기를 인터넷으로 컴퓨터에 연결시키는 사물인터넷(internet of things; IoT) 시대를 준비하고 있다. 자동운행 차, 로봇 의사, 로봇 선생님 등 현재와는 획기적으로 다른 사회가 예견되는데 이를 4차 산업혁명 기술사회로 부른다.
이러한 기술의 발전은 과거에는 상상도 할 수 없었던 크기의 빅데이터(big data)를 생성하였다. 빅데이터의 대표적인 예로는 전 세계인이 많이 사용하고 있는 구글의 검색기록 데이터, 스마트폰의 소셜미디어 데이터, 인터넷의 웹로그(web log) 데이터, 글로벌 통신회사의 통화기록 데이터 등이 있다. 향후 4차 산업혁명이 진행되면서 빅데이터는 점점 더 커지고 많아질 전망이고 이 빅데이터를 효율적으로 활용하여 과거에는 불가능했던 미래에 대한 초예측(hyper-forecasting)이 가능할 전망이다. 4차 산업혁명 사회에서는 어떻게 빅데이터를 유효적절하게 만들고 이를 사용하느냐에 따라 각 개인, 단체, 기업, 나아가 국가의 성패가 달려 있다.
문자 및 숫자 등으로 이루어지는 데이터는 인류가 문자를 발명하여 역사를 기록하면서 생겨났다고 볼 수 있다. 고대의 이집트, 그리스 로마 등에서는 인구수, 농지 면적 등의 데이터를 만들어 국가 경영에 사용한 기록이 있다. 이러한 단순한 데이터 활용은 17세기이후 수학의 확률론 발전에 힘입어 통계학(statistics)이란 학문으로 발전하였다. 현대통계학은 데이터를 효율적으로 수집하고, 이를 정리, 요약한 후 분석을 하여 불확실한 상황의 의사결정에 대해 여러 가지 확률적 모형을 이용하여 과학적인 판단을 내릴 수 있도록 도움을 주는 학문이다.
4차 산업혁명 사회에서도 현실의 불확실한 상황에 대한 의사결정을 할 때 전통적인 통계학의 기법이 주를 이룬다. 하지만 금세기에 출현한 빅데이터의 분석은 데이터의 양도 엄청나고 다양해 단지 통계학적인 접근만으로 그 활용을 모두 할 수는 없다. 이러한 빅데이터의 분석을 위해서는 전통적인 통계학의 이론과 수학의 최근 이론, 컴퓨터 과학, 그리고 분석된 결과를 효율적으로 활용하기 위해서는 경영학 등 관련 학문도 같이 적용되어야 한다. 이와 같이 여러 학문 분야가 융합하여 금세기에 출현한 빅데이터를 분석해 현실에 응용하는 학문을 데이터과학(data science)이라 부른다.
| 데이터과학(data science)은 금세기에 출현한 빅데이터를 분석하여 현실에 활용하기 위해 통계학, 수학, 컴퓨터과학 등이 융합된 학문 분야이다. |
빅데이터를 분석하여 현실에 응용하는 데이터과학이 활용된 예는 많이 있다.
– 구글의 검색 엔진에 자동차 구입에 관한 질문을 조사하여 다음 달 미국서 판매되는 자동차 모델의 수를 예측하였다.
– 구글 검색 엔진에 감기약을 검색한 결과를 분석하여 올해 미국서 유행하는 감기의 전파 경로를 지도에 표시하였다. 이를 구글 플루라 부르는데 미국 정부의 질병관리본부보다 앞서서 감기의 전파경로를 예측하여 세상을 놀라게 하였다.
– 베네수엘라의 한 식품체인 회사는 분산되었던 각 지점의 데이터를 통합 분석하여 재고관리 개선과 이에 맞는 상품 판매 전략을 수립하여 매출이 30%나 증가하는 성과를 이루었다.
– 한 온라인 쇼핑몰은 웹로그를 분석하여, 회원 고객이 어떤 취향을 가지고 어떤 제품에 관심이 있는지 파악하여 고객 개개인에 맞는 맞춤형 광고를 하여 매출이 증가하였다.
– 한 원유 탐사회사에서 테라바이트 규모의 지질학 데이터를 분석해 원유 시추의 성공률을 높였다.
– 남아프리카의 어느 보험회사에서 기존 보험금 청구 빅데이터를 분석하여 보험사기 가능성이 있는 사건을 찾을 수 있는 알고리즘을 구현하였다. 이를 활용하여 많은 보험사기를 적발하였고 심지어 대형 보험사기 조직을 적발하기도 하였다.
– 미국의 한 대학에서 온라인 수업에서 학생들이 시스템에 클릭하는 정보를 분석하여 학생 개개인의 학습 성과를 모니터링하고 학생의 이해도에 맞춘 수준별 수업 내용을 제안하고, 향후 수강할 과목 등을 학생별로 제안하였다. 이 결과 전공별 학위 취득률이 많이 향상되었다.
덴마크의 한 풍력발전 회사는 기존 발전기에서 축적된 페타바이트 규모의 데이터를 분석하여 풍력발전기에 대한 날씨와 위치의 영향을 정확히 파악하고 이를 바탕으로 풍력발전기의 부지 선정 및 운영을 효율적으로 할 수 있게 되었다.
데이터과학은 여러 학문의 융합이어서 데이터과학을 연구하기 이해서는 여러 학문 분야를 두루 많이 알아야 한다. 구체적으로 최근 빅데이터의 분석에 많이 사용되는 기법은 통계학의 가설검정, 다변량분석, 선형모형 등의 전통적인 이론과 함께 수학에서 발전한 신경망(neural network), 지지벡터기계(support vector machine), 컴퓨터 과학의 데이터베이스(database), 분산컴퓨팅(distributed computing), 기계학습(machine learning), 인공지능(artificial intelligence) 등이다.
여러 학문의 융합인 데이터과학을 공부하는 것은 쉽지 않다. 잘못하면 이 분야도 많이 알지 못하고 저 분야도 제대로 많이 모를 위험이 있다. 그러나 데이터과학을 잘 공부한 사람은 21세기가 필요로 하는 인재가 될 것임이 틀림없다.
이 책에서는 데이터과학에 입문하는 초보자를 위해 데이터과학의 기초인 데이터 시각화와 데이터 정리 방법을 소개하고, 표본을 이용한 모집단의 특성을 추론하는 통계적 의사결정 모형을 소개하고자 한다. 표 1.1은 이 책의 구성을 보여준다.

표 1.1.1 이 책의 구성
2장은 막대, 원, 띠, 꺾은선 그래프 등의 범주형 데이터 시각화를 다룬다. 3장은 히스토그램, 줄기와 잎 그림, 산점도 등의 연속형 데이터 시각화를 다룬다. 4장은 표/측도를 이용한 데이터 정리를 소개한다.
5장은 데이터에 대한 확률분포 모형을 소개하고, 6장은 표본과 모집단의 관계에 대해서 살펴보고 표본통계량에 대한 분포와 이를 바탕으로 모집단 모수에 대한 추정을 설명한다. 7장에서 9장까지는 연속형 변량에 대한 모수적 가설검정을 설명하고, 10장에서는 연속형 변량의 비모수적 가설검정, 11장은 범주형 변량에 대한 가설검정을 설명한다. 12장은 두 변량에 대한 상관 및 회귀분석을 설명한다.
1.2 데이터의 구분
데이터는 관심의 대상이 되는 사물이나 사건의 속성을 일정한 규칙에 의해 관찰하거나 측정한 값들이다. 이러한 사물이나 사건의 속성을 변수 또는 변량(variable)이라고 한다. 예를 들어, 어느 대학 재학생의 성별과 신장을 측정하였다면 여기에는 두개의 변량(성별, 신장)이 있다. 성별에 대한 측정값은 ‘남’, ‘여’, ‘여’, ‘남’, …. 과 같은 형태이고, 신장에 대한 측정값은 180cm, 165cm, 158cm, 175cm, … 와 같은 형태일 것이다.
‘성별’과 같은 변량의 데이터를 이산형 데이터(discrete data), 신장과 같은 변량의 데이터를 연속형 데이터(continuous data)로 구분한다. 성별과 같은 이산형 변량은 모든 가능한 측정값이 유한개 또는 셀 수 있는 변량을 뜻하며, 각각의 값에 대한 도수분포가 의미 있다. 이산형 데이터 중 유한개의 범주 형태를 갖는 경우를 범주형 데이터(categorical data)라고 한다.
데이터를 구분하는 이유는 데이터의 종류의 따라 처리하는 방법과 분석 방법이 다르기 때문이다. 이 책의 2장은 범주형 데이터의 시각화를 다루고, 3장은 연속형 데이터의 시각화를 다룬다. 4장에서는 범주형 데이터의 요약인 도수분포표와 교차표를 다루고, 표 및 측도를 이용한 연속형 데이터 정리를 설명한다. 5장에서 10장 그리고 12장은 연속형 데이터의 통계 분석 이론을 설명한다. 11장은 범주형 데이터의 분석 이론을 설명한다.
소프트웨어를 이용한 데이터 분석을 위해 범주형 데이터는 원시 데이터(raw data)와 요약 데이터로 구분한다. 예를 들어, 어느 초등학교 한 학급 학생 10명의 성별을 남, 여, 남, … 등으로 조사하여 다음과 같이 엑셀 시트에 정리하였다면 이를 원시 데이터라 한다. 여기서 변량의 이름 ‘성별’을 변량명(variable name), ‘남’ 또는 ‘여’와 같은 값을 변량값(variable value)이라 부른다.
표 1.2.1 성별을 조사하여 엑셀에 정리한 원시 데이터
| 성별 |
| 남 |
| 여 |
| 남 |
| 여 |
| 남 |
| 남 |
| 남 |
| 여 |
| 여 |
| 남 |
표 2.1의 한 학급 성별 데이터는 ‘남’이 6명이고 ‘여’가 4명이다. 이렇게 빈도수를 정리한 데이터를 요약 데이터(summary data), 또는 성별의 도수분포표(frequency table)라고도 부른다. 엑셀에서는 일반적으로 다음과 같이 정리한 데이터를 이용한다.
표 1.2.2 한 학급의 성별을 정리 요약한 데이터. 또는 성별 도수분포표
| 성별 | 학생수 |
| 남 | 6 |
| 여 | 4 |
1.3 『eStat』 데이터 분석
데이터 분석을 위해서는 소프트웨어의 도움이 필수적이다. 특히 빅데이터 분석을 위해서는 전문적인 통계분석 모듈을 많이 가지고 있는 통계 패키지(statistical package)가 반드시 필요하다. 현재 빅데이터 분석을 위해서는 SAS, SPSS, R과 같은 통계패키지가 많이 사용되고 있다.
하지만 이들 통계패키지들은 초보자가 배우기는 쉽지 않고, SAS와 SPSS는 상업용이어서 엄청난 고가이다. 그리고 이러한 통계패키지는 빅데이터 분석의 핵심인 통계학 교육에 필요한 모듈의 기능은 거의 없다고 할 수 있다. 통계학 교육을 위해서는 일부 개인들이 부분적인 기능의 소프트웨어를 만들고 있으나 초중·고·대·일반인들이 모두 사용할 수 있는 종합적인 통계교육용 소프트웨어는 아직 없었다.
『eStat』은 데이터과학을 초등생부터 대학 및 일반인까지 쉽게 교육하기 위하여 만든 통계패키지 + 교육용소프트웨어이다. 데이터가 주어지면 단지 마우스 클릭만으로 그래프를 그릴 수 있고, 동적인 데이터 시각화를 경험할 수 있으며, 데이터에 대한 통계 분석 및 처리 실습까지 가능하다.
『eStat』은 통계패키지와 같이 데이터 처리가 가능하며, 통계학 이론에 대한 이해를 돕기 위한 다양한 시뮬레이션 모듈을 포함하고 있다. 이항분포와 정규분포가 무엇인지 보여주는 시뮬레이션, 대수의 법칙, 중심극한정리, 구간추정의 의미를 보여주는 시뮬레이션, 회귀분석의 이상값의 영향을 관찰할 수 있는 시뮬레이션 등이다.
『eStat』은 각급 교과서에 있는 많은 예를 포함하고 있으며, 웹 기반이어서 사용자들은 언제 어디서나 PC, 태블릿, 또는 스마트폰으로 이용할 수 있다. 『eStat』은 무료로 서비스하고 있고 다국적 언어를 지원하며 현재 한국어, 영어, 일본어, 중국어, 불어, 독어, 스페인어, 베트남어, 인도네시아 등 10개 언어가 가능하다.
1.3.1절에서는 『eStat』의 기본 운용에 대해서 살펴본다. 『eStat』에 대한 자세한 설명과 동영상은 다음 링크를 참조하라.
설명 : http://www.estat.me/estat/ExLearning/index.html
동영상 : http://www.estat.me/estat/ExLecture/index.html
이 책의 2장서부터는 각 장마다 적절한 예를 이용하여 어떻게 『eStat』으로 현실 데이터를 분석할 수 있는지 소개한다.
1.3.1 『eStat』 기본 운용
가. 시스템 들어가기
『eStat』 시스템은 HTML5, CSS3, JavaScript로 만든 웹 소프트웨어라서 반드시 웹브라우저가 필요하다. 현재 통용되는 많은 웹브라우저 중에서 HTML5 표준을 100% 잘 지키는 것은 구글(Google)사의 크롬(Chrome)이어서 가능하면 크롬 이용을 권장한다. MS 엣지(Edge)와 같은 브라우저에서도 『eStat』이 작동은 되나 일부 기능이 안 될 수 있다.
모니터에서 크롬 아이콘 ![]() 을 클릭한 후 나타나는 주소창에 www.estat.me를 입력하면 <그림 1.3.1>과 같은 『eStat』의 주화면이 나타난다.
을 클릭한 후 나타나는 주소창에 www.estat.me를 입력하면 <그림 1.3.1>과 같은 『eStat』의 주화면이 나타난다.
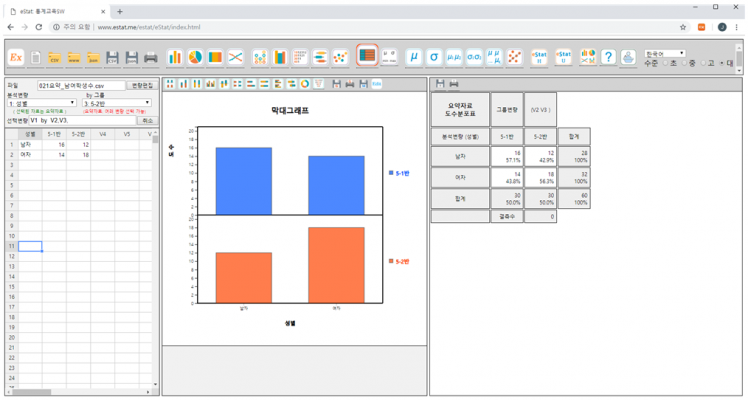
<그림 1.3.1> 『eStat』의 주화면
주화면 윗부분에는 여러 가지 아이콘들이 있다. 일반적인 소프트웨어에서 많이 사용하는 드롭다운 방식의 메뉴를 사용하지 않고 아이콘들을 펼쳐 놓은 것은 사용자들이 한 눈에 『eStat』에서 할 수 있는 작업을 보기 쉽게 한 것이다. 다만 고등학교 수준이나 대학 수준은 여러 가지 메뉴가 있을 수 있어 별도의 아이콘『eStatH』 ![]() 와 『eStatU』
와 『eStatU』 ![]() 을 만들었는데 이것을 클릭하면 세부 메뉴를 새로운 윈도우창에 띄워준다.
을 만들었는데 이것을 클릭하면 세부 메뉴를 새로운 윈도우창에 띄워준다.
주화면의 왼쪽은 데이터 입력을 위한 시트창이다. 시트창 위에는 각 분석별로 필요한 ‘분석변량’이나 ‘by 그룹’을 선택하는 창이 있다. 주화면 가운데는 데이터 분석를 보여주는 그래프창, 오른쪽은 저장이 필요한 그래프나 표를 보관해 놓는 분석결과 로그(log)창이 있다.
나. 데이터 입력 / 저장 / 불러오기
『eStat』에서 데이터 만들기
주화면 좌측에 있는 시트에 데이터를 입력한다. 이 시트에서 행(row)은 관찰 대상, 열(column)은 변량을 나타낸다. 마우스로 1행 1열을 클릭하면 이 셀에 대한 행과 열이 다른 부분과 달리 진한 색으로 표시되고, 셀에는 직사각형 형태의 외곽선이 생기는데 이를 커서(cursor)라 한다. 이는 커서가 위치하여 있는 1행1열에 데이터를 입력받을 준비가 되어 있다는 것을 의미한다. 이 커서(cursor)는 화살표키 ![]() 나
나 ![]() 를 사용하면 셀에서 셀로 또는 페이지 단위로 커서를 이동시킬 수 있다.
를 사용하면 셀에서 셀로 또는 페이지 단위로 커서를 이동시킬 수 있다.

<그림 1.3.2> 『eStat』의 데이터 입력을 위한 시트
『eStat』에서 허용하는 데이터의 최대수는 9999개, 변량의 최대수는 20개이다. 데이터의 입력은 왼쪽 위의 1행 1열(관찰대상1, 변량1)서부터 데이터를 입력한 후, 아래 방향 화살표키(![]() ) (또는
) (또는 ![]() 키)를 이용하여 커서를 밑(2행 1열)으로 이동시켜 다음 데이터를 입력한다. 같은 방법으로 화살표키(
키)를 이용하여 커서를 밑(2행 1열)으로 이동시켜 다음 데이터를 입력한다. 같은 방법으로 화살표키(![]() )를 이용하여 커서를 이동하면서 모든 데이터를 각 셀에 입력하면 된다.
)를 이용하여 커서를 이동하면서 모든 데이터를 각 셀에 입력하면 된다.
<그림 1.3.3>은 두 학급의 남 여 학생수를 입력한 예이다. 각 셀에는 데이터로 문자나 숫자를 입력할 수 있다.
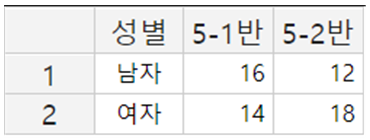
<그림 1.3.3> 『eStat』의 데이터 입력
막대, 원, 띠그래프는 문자 데이터을 이용해서 그래프를 그릴 수 있으나. 점그래프, 히스토그램, 줄기와 잎 그림은 반드시 숫자 데이터를 이용하여야 한다. 단 그룹변량은 문자 데이터를 이용할 수 있다.
<그림 1.3.3>에서는 데이터가 시트 화면에 모두 보인다. 만일 데이터가 커서 시트 화면에 일부만 나타날 경우에는 ![]() 키를 사용하여 위․아래로 한 화면씩 이동하여 볼 수 있고,
키를 사용하여 위․아래로 한 화면씩 이동하여 볼 수 있고, ![]() 키와 화살표키(
키와 화살표키(![]() )를 같이 눌러 데이터의 위/아래/왼쪽/오른쪽 끝으로 쉽게 이동할 수 있다.
)를 같이 눌러 데이터의 위/아래/왼쪽/오른쪽 끝으로 쉽게 이동할 수 있다.
변량명 및 변량값명의 입력
데이터의 입력이 끝난 후 『eStat』를 이용하여 데이터 처리를 하면 결과 출력은 변량이름으로 변량1(또는 V1), 변량2(또는 V2), 변량3(또는 V3) … 라는 고유 이름이 나타난다. 이러한 고유 이름 대신 변량의 실제이름이나 그 변량 값에 대한 설명을 데이터처리 전에 입력하면 결과를 분석하기가 쉽다.
<그림 1.3.3>에서 변량명의 입력은 데이터 입력 후에 ‘변량편집’ 버튼을 클릭하여 나타나는 <그림 1.3.4>의 대화상자창에서 변량명 V1 대신 ‘성별’을 입력하고, 콤보박스에서 V2를 선택한 후 ‘5-1반’, V3를 선택한 후 ‘5-2반’을 입력하면 된다.
![]()

<그림 1.3.4> 변량편집 대화상자
원시 데이터인 경우 변량편집 창을 이용하면 변량값에 대한 변량값명을 지정할 수 있다.
데이터의 수정
만일 한 셀에 입력된 데이터를 모두 수정하고 싶으면, 원하는 셀에 커서를 위치한 후 새 데이터를 입력하면 된다. 만일 한 셀에 입력된 데이터의 일부분만 수정하고 싶다면 원하는 셀을 마우스로 두 번 누른 후 화살표키(![]() )를 이용하여 글자 사이를 이동하면서 수정을 하면 된다.
)를 이용하여 글자 사이를 이동하면서 수정을 하면 된다.
데이터의 저장
시트에서의 데이터 입력은 컴퓨터의 주기억장치(main memory)를 이용하기 때문에 전원이 끊어지게 되면 이 기억장치에 들어 있는 내용은 모두 없어진다. 그러므로 데이터를 모두 입력한 후에는 이를 반드시 하드 디스크나 USB와 같은 보조 기억장치에 저장하여야 한다.
『eStat』에서는 파일이름 박스에 파일명을 입력하고 CSV 저장 아이콘 ![]() 을 클릭하면 변량명과 데이터를 엑셀의 CSV 형식으로 저장한다. 이때 파일명의 확장자는 csv여야 한다.
을 클릭하면 변량명과 데이터를 엑셀의 CSV 형식으로 저장한다. 이때 파일명의 확장자는 csv여야 한다.
만일 변량값명까지 지정하였다면 JSON 저장 아이콘 ![]() 을 클릭하여 JSON 형식으로 저장한다. 이때 파일명의 확장자는 json이다. 파일이 저장되는 지점은 시스템의 ‘download’ 폴더가 된다.
을 클릭하여 JSON 형식으로 저장한다. 이때 파일명의 확장자는 json이다. 파일이 저장되는 지점은 시스템의 ‘download’ 폴더가 된다.
저장된 파일 불러오기
내 컴퓨터에 저장된 CSV 형식으로 저장된 파일은 CSV 불러오기 아이콘 ![]() 을 이용하여 불러올 수 있다.
을 이용하여 불러올 수 있다.
다른 서버 컴퓨터에 저장된 CSV 형식으로 저장된 파일은 www 불러오기 아이콘 ![]() 을 이용하여 불러올 수 있다.
을 이용하여 불러올 수 있다.
내 컴퓨터에 저장된 JSON 형식으로 저장된 파일은 JSON 불러오기 아이콘 ![]() 을 이용하여 불러올 수 있다.
을 이용하여 불러올 수 있다.
다. 데이터 분석
요약 데이터의 분석
<그림 1.3.3>과 같은 데이터를 범주형 요약 데이터라 부른다. 시트에서 마우스로 변량명 ‘성별’과 ‘5-1반’ ‘5-2반’을 차례로 클릭하면 선택변량 박스에 ‘V1 V2 V3’ 가 나타나고 기본적으로 선택된 <그림 1.3.5>와 같은 남녀별 학생수에 대한 수직형 막대그래프(![]() )가 나타난다. 시트위의 변량선택 박스에서 ‘분석변량’을 ‘성별’ ‘by 그룹’ 변량을 ‘5-1반’ ‘5-2반’을 차례로 선택하여도 된다.
)가 나타난다. 시트위의 변량선택 박스에서 ‘분석변량’을 ‘성별’ ‘by 그룹’ 변량을 ‘5-1반’ ‘5-2반’을 차례로 선택하여도 된다.
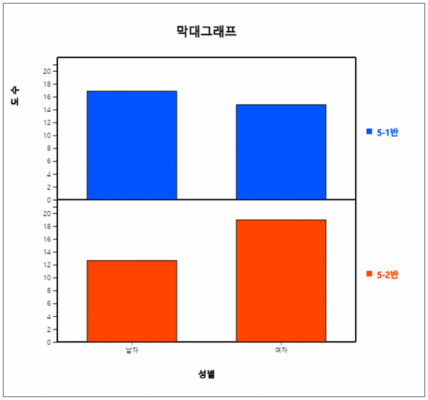
<그림 1.3.5> 5-1반과 5-2반의 남녀 학생수의 막대그래프
그래프의 제목은 원하는 내용으로 수정할 수 있다. 그래프창 위의 편집 아이콘 ![]() 을 클릭하면 그래프 하단에 다음과 같은 편집 대화상자가 나타난다. 여기에서 주제목, y축제목, x축제목을 바꾼 후 ‘수정’ 버튼을 클릭한다.
을 클릭하면 그래프 하단에 다음과 같은 편집 대화상자가 나타난다. 여기에서 주제목, y축제목, x축제목을 바꾼 후 ‘수정’ 버튼을 클릭한다.

<그림 1.3.6> 그래프 제목 편집 대화상자
원시 데이터의 분석
표 1.3.1과 같은 원시데이터의 처리도 유사하다. 시트의 V1열에 데이터 입력을 한다. 변량명의 입력은 시트 위의 ‘변량편집’을 클릭한 후 변량명 박스에 V1대신 ‘성별’을 입력한다.
표 1.3.1 한 학급의 성별을 조사하여 엑셀에 정리한 원시 데이터
| 성별 |
| 남 |
| 여 |
| 남 |
| 여 |
| 남 |
| 남 |
| 남 |
| 여 |
| 여 |
| 남 |
– 마우스로 변량명 ‘성별’을 클릭하면 선택변량 박스에 첫 번째 변량의 선택을 의미하는 ‘V1’이 나타나고 기본적으로 선택된 수직형 막대그래프 (![]() ) 가 <그림 1.3.7>과 같이 그려진다. 원시 데이터의 남·여 학생수를 세어서 막대그래프를 그린 것이다.
) 가 <그림 1.3.7>과 같이 그려진다. 원시 데이터의 남·여 학생수를 세어서 막대그래프를 그린 것이다.
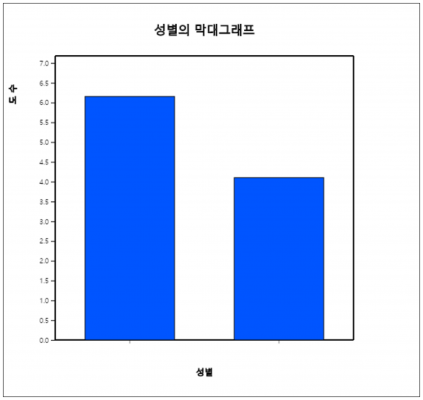
<그림 1.3.7> 성별 막대그래프
현재 성별 변량이 선택된 상태에서 아이콘 ![]() 을 클릭하면 원그래프가 나타나고,
을 클릭하면 원그래프가 나타나고, ![]() 을 클릭하면 띠그래프,
을 클릭하면 띠그래프, ![]() 을 클릭하면 꺾은선그래프가 나타난다.
을 클릭하면 꺾은선그래프가 나타난다.
![]()
라. 분석결과 저장 및 인쇄
『eStat』에서 그래프창에 표시된 분석 결과를 저장하려면 그래프창 위의 저장 아이콘 ![]() 을 클릭한다. 그러면 그래프가 png 파일로 저장되는데 주화면 왼쪽 밑에
을 클릭한다. 그러면 그래프가 png 파일로 저장되는데 주화면 왼쪽 밑에 ![]() 와 같이 표시된다. 저장되는 위치는 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 이어서 다른 그래프를 저장하면 다운로드 폴더에 eStatGraph(1).png 등과 같이 괄호 안의 번호가 증가되면서 저장된다.
와 같이 표시된다. 저장되는 위치는 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 이어서 다른 그래프를 저장하면 다운로드 폴더에 eStatGraph(1).png 등과 같이 괄호 안의 번호가 증가되면서 저장된다.
그래프창의 결과를 인쇄하려면 그래프창 위의 인쇄 아이콘 ![]() 을 클릭한다. 그러면 <그림 3.8>과 같은 윈도우에서 제공하는 인쇄를 위한 화면이 나타나고 여기서 ‘인쇄’ 버튼을 클릭하면 프린터에 그래프창 결과가 인쇄된다.
을 클릭한다. 그러면 <그림 3.8>과 같은 윈도우에서 제공하는 인쇄를 위한 화면이 나타나고 여기서 ‘인쇄’ 버튼을 클릭하면 프린터에 그래프창 결과가 인쇄된다.
<그림 1.3.8> 그래프창의 인쇄
그래프창의 결과는 필요시 오른쪽의 로그창으로 이동한 후 필요시 인쇄할 수 있다. 그래프창 위의 이동 아이콘 ![]() 을 누르면 현재 그래프창에 있는 내용이 로그창으로 이동한다.
을 누르면 현재 그래프창에 있는 내용이 로그창으로 이동한다.
로그창에 있는 내용을 저장하려면 로그창 위의 저장 아이콘 ![]() 을 클릭한다. 그러면 로그창의 내용이 html 파일로 저장되는데 주화면 왼쪽 밑에
을 클릭한다. 그러면 로그창의 내용이 html 파일로 저장되는데 주화면 왼쪽 밑에 ![]() 와 같이 표시된다. 저장되는 위치는 역시 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 저장된 html 파일은 MS Word나 아래아한글에서 불러올 수 있다.
와 같이 표시된다. 저장되는 위치는 역시 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 저장된 html 파일은 MS Word나 아래아한글에서 불러올 수 있다.
로그창의 결과를 인쇄하려면 로그창 위의 인쇄 아이콘 ![]() 을 클릭한다. 그러면 윈도우에서 제공하는 인쇄를 위한 화면이 나타나고 여기서 ‘인쇄’ 버튼을 클릭하면 프린터에 로그창 결과가 인쇄된다.
을 클릭한다. 그러면 윈도우에서 제공하는 인쇄를 위한 화면이 나타나고 여기서 ‘인쇄’ 버튼을 클릭하면 프린터에 로그창 결과가 인쇄된다.
마. 시스템 나오기
『eStat』시스템을 끝내려면 브라우저를 종료하면 된다. 즉, 브라우저 오른쪽 위의 ![]() 버튼을 클릭한다.
버튼을 클릭한다.